Spadki ruchu, strony utkwione jako Discovered not indexed oraz CWV wpadające w czerwień to klasyczne problemy techniczne. Zwykle nie chodzi o treści. Skorzystaj z tej listy kontrolnej audytu SEO technicznego, aby szybko znaleźć i naprawić problemy z crawlowaniem, Core Web Vitals i indeksacją, a potem utrzymać je w ryzach.
Przygotowanie przed audytem
- Zapisz cele i kluczowe szablony. Priorytetyzuj według wartości biznesowej: produkt, kategoria/kolekcja, artykuł, lokalizacja i checkout. Wypisz po kilka przykładowych adresów URL dla każdego, aby testować konsekwentnie.
- Zweryfikuj dostęp do Google Search Console i GA4. W GSC potwierdź dostęp na poziomie usługi do Indexing > Pages, Core Web Vitals, Sitemaps i URL Inspection. W GA4 utwórz Explore z landing page + source/medium, aby powiązać poprawki z ruchem.
- Zrób snapshot robots, map witryny i nagłówków. Zapisz stan bieżący w notatkach lub w kontroli wersji:
curl -I https://example.com/,curl https://example.com/robots.txticurl -I https://example.com/sitemap.xml. Sprawdź status 200, content-type, cache-control oraz to, że mapy witryny zawierają wyłącznie kanoniczne adresy URL. - Potwierdź kanoniczny host, protokół i politykę parametrów. Zdecyduj https only, www lub bez www, zasady ukośników końcowych oraz które parametry UTM lub filtry są dozwolone. Wymuś to za pomocą 301 i kanonicznych odwołujących się do siebie. Udokumentuj, które parametry są usuwane lub zachowywane.
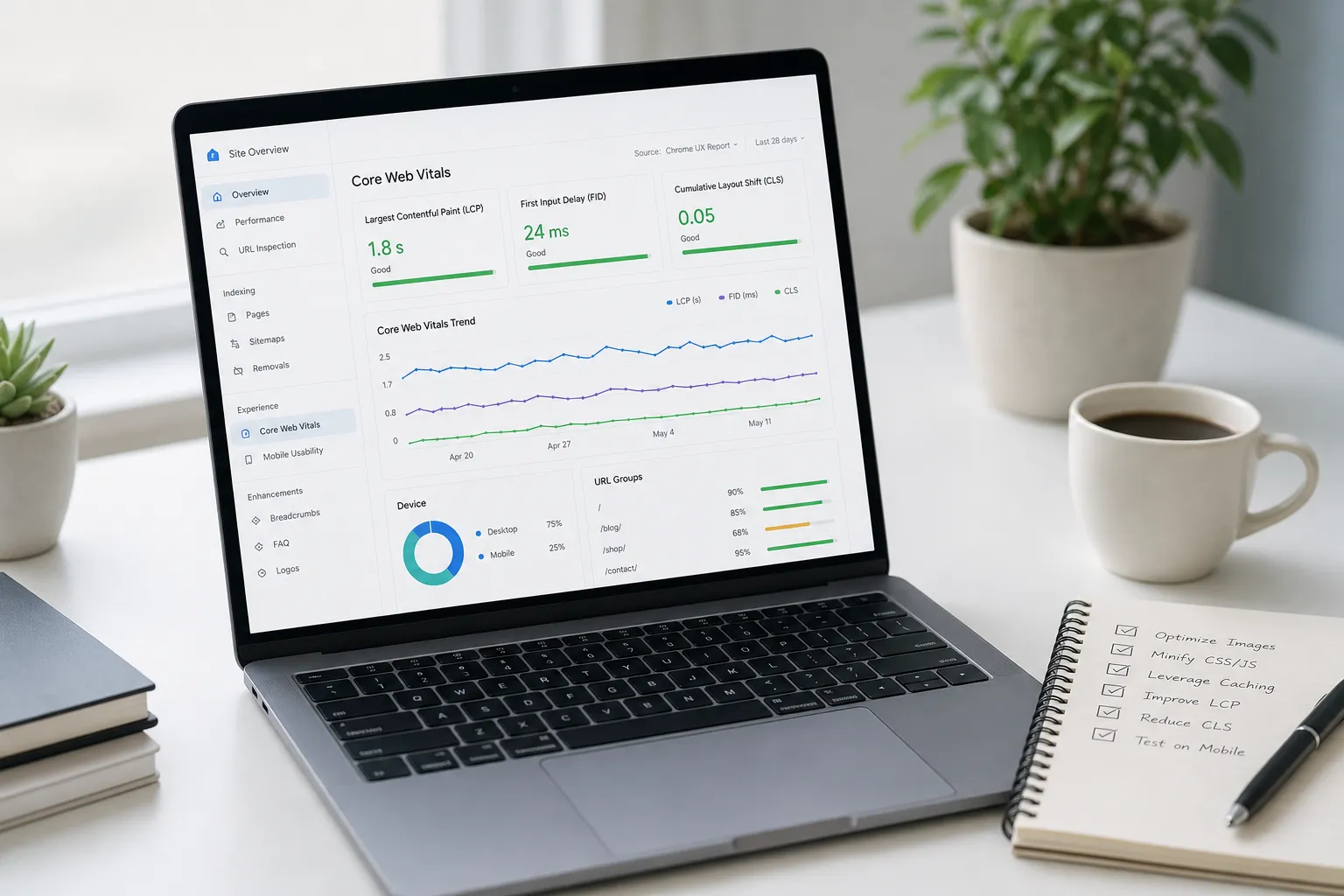
- Zanotuj bieżące Core Web Vitals i statystyki crawlowania. Zapisz progi LCP, INP i CLS dla szablonów (dobre: LCP ≤ 2.5s, INP ≤ 200ms, CLS ≤ 0.1). W GSC Settings > Crawl stats zanotuj średnią liczbę żądań dziennie oraz rozmiar i czas odpowiedzi.
- Wypisz ograniczenia platformy i wtyczki. Ustal, kto kontroluje renderowanie, cache i routing. Przykłady: Next.js SSR z cache CDN, Shopify Liquid z app proxies, WordPress z wtyczką cache. Dzięki temu nie będziesz forsować poprawek, których nie da się wdrożyć.
- Ustal plan staging i rollback. Staging powinien być noindexed lub za basic auth, najlepiej z allowlistingiem IP. Miej plan przywracania dla przekierowań, robots i szablonów. Oznaczaj każde wdrożenie timestampem, aby móc powiązać je z metrykami.
- Ustal właścicieli i rytm prac. Przydziel właścicieli dla crawlowania, CWV i indeksacji. Ustal cotygodniową triagę, comiesięczny release train i kwartalny głęboki audyt. Zdefiniuj SLA dla krytycznych regresji.
Przegląd crawlowania i logów
- Wykonaj pełne crawlowanie z renderowaniem JavaScriptu. Użyj crawlera, który renderuje JS. Złap zarówno surowe HTML, jak i HTML po renderowaniu. Porównaj tytuł/H1, linki i liczbę słów, aby zobaczyć, co Googlebot może pominąć, gdy renderowanie zawodzi.
- Przeanalizuj dyrektywy robots i meta tagi. Sprawdź robots.txt pod kątem niezamierzonego
Disallow: /na produkcji oraz blokad per-ścieżka ukrywających paginację lub filtry. Na stronie zweryfikuj<meta name="robots" content="index,follow">na szablonach indeksowalnych i usuń zbłąkanenoindexlubnofollow. - Znajdź łańcuchy przekierowań i marnotrawstwo kodów statusu. Wyeksportuj łańcuchy 3xx i zredukuj je do jednego skoku 301. Napraw 4xx na linkach wewnętrznych i skoki 5xx. Wymuś przejście http do https i kanonizację hosta jednym skokiem, a po potwierdzeniu stabilności włącz HSTS.
- Wydobądź osierocone i słabo podlinkowane strony. Porównaj dane z crawla z adresami URL w mapach witryny. Każda strona z zerową liczbą linków wewnętrznych potrzebuje przynajmniej jednego linku z strony hubowej, kategorii lub stopki. Dodaj breadcrumbs i linki kontekstowe, aby zwiększyć odkrywalność i trafność.
- Porównaj adresy z map witryny z odkrytymi adresami. XML sitemaps powinny zawierać wyłącznie kanoniczne adresy 200. Usuń niekanoniczne, parametry oraz 3xx/4xx. Jeśli znajdziesz wartościowe adresy, których nie ma w mapie, dodaj je i wyślij ponownie.
- Przejrzyj logi serwera pod kątem zachowania Googlebota. Próbkuj ostatnie logi, aby potwierdzić, że Googlebot i Googlebot-Image trafiają w ważne sekcje, a nie toną w parametrach. Typowy hit wygląda tak:
Zwracaj uwagę na powtarzające się 404, wolne 200 (> 1s TTFB) i marnotrawstwo na nieskończonych filtrach.66.249.xx.xx - - [20/Jun/2026:12:01:02 +0000] "GET /category/widget?sort=az HTTP/1.1" 200 4321 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" - Ustandaryzuj kanoniczne i hreflang. Każda indeksowalna strona powinna mieć self-referencing canonical. Jeśli celujesz w wiele lokalizacji, dodaj spójne pary hreflang i x-default. Nie kieruj hreflang na adresy niekanoniczne.
- Przejrzyj parametry i adresy fasetowe. Ogranicz przestrzeń crawlowania. Zezwól na crawl faset, których szukają użytkownicy, zablokuj nieskończone kombinacje. Opcje: zablokuj hałaśliwe wzorce w robots.txt, dodaj
noindex,followdo cienkich faset i ustaw canonical z powrotem do bazowej kategorii.
RankGoat cyklicznie crawluje Twoją witrynę, wykrywa marnotrawstwo crawla i łańcuchy przekierowań oraz koryguje typowe błędy robots i canonical, zanim kosztują ruch.
Kontrole Core Web Vitals
- Zacznij od danych polowych, potem potwierdź testami labowymi. Użyj CrUX i GSC do real-user LCP, INP i CLS. Odtwórz problemy w Lighthouse w trybie mobilnym z ograniczeniami, aby wyizolować blokujące zasoby i długie zadania.
- Wskaż element LCP dla każdego szablonu. Zidentyfikuj obraz hero lub nagłówek. Wczytaj go wcześniej za pomocą
<link rel="preload" as="image" imagesrcset="..." fetchpriority="high" href="...">, używaj WebP lub AVIF, mocno kompresuj i inline'uj krytyczne CSS, aby uniknąć blokowania renderowania. - Usuń przesunięcia układu u źródła. Rezerwuj miejsce dzięki wymiarom intrinsic lub
aspect-ratio, unikaj późnego wstrzykiwania banerów lub zgód i stabilizuj fonty przezfont-display: swap. Zrób audyt pasków sticky, które spychają treść. - Walcz z INP przez redukcję pracy głównego wątku. Odłóż niekrytyczne skrypty, podziel bundlery, oznacz pasywne listenery i rozbijaj zadania > 50 ms. Priorytetyzuj handlery wejścia i unikaj synchronicznych widżetów third-party przy pierwszej interakcji.
- Ogranicz skrypty i tagi zewnętrzne. Wypisz każdy tag, właściciela i cel. Usuń duplikaty, ustal budżet ładowania i opóźnij wszystko, co nie jest potrzebne do pierwszego malowania. Użyj server-side tagging lub lekkiego loadera, gdzie to możliwe.
- Dobierz rozmiary i leniwe ładowanie mediów. Stosuj responsywny
srcsetisizes,loading="lazy"orazdecoding="async", a obrazy hero ogranicz do szerokości widocznego viewportu. Kompresuj wideo lub zastąp je plakatem click-to-load. - Wzmocnij cache i dostarczanie. Serwuj z CDN, włącz kompresję i ustaw
Cache-Controlz rozsądnymmax-age/s-maxage. Używaj HTTP/2 lub HTTP/3, preconnect do kluczowych originów i unikaj paramów cache-busting na statycznych zasobach. - Testuj najpierw na mobile. Waliduj na profilu urządzenia ze średniej półki, ~1.6 Mbps i 300 ms RTT. Sprawdzaj CWV per szablon i budżety wagi strony. Upewnij się, że pierwsze wejście pozostaje responsywne na stronach z ciężkim przewijaniem.
RankGoat monitoruje Core Web Vitals per szablon, dostarcza bezpieczne optymalizacje i alarmuje przy regresjach, abyś nie musiał pilnować wykresów.
Diagnostyka indeksacji
- Sprawdź kluczowe adresy URL w GSC. Użyj URL Inspection, aby potwierdzić crawl, renderowanie, wybrany canonical i status indeksacji. Jeśli Google wybiera inny canonical, porównaj treść, linkowanie wewnętrzne i kanoniki, aby zrozumieć konflikt sygnałów.
- Przeanalizuj koszyki Page indexing. Dla Discovered, not indexed dodaj linki wewnętrzne i umieść w mapie witryny. Dla Crawled, not indexed pogłęb treść i usuń sygnały duplikacji. Dla Duplicate without user-selected canonical napraw kanoniki i przekierowania.
- Zaostrzyj zasady kanonikalizacji. Używaj self-referential
<link rel="canonical" href="...">na stronach indeksowalnych. Ujednolić ukośniki końcowe w całej witrynie. Dla wariantów stosuj 301 i unikaj 302 lub przekierowań JS przy trwałych przenosinach. - Kontroluj thin, duplikaty i soft 404. Oznacz noindex strony tagów i wyników wyszukiwania. Konsoliduj bliskie duplikaty do adresu głównego. Zwracaj 404 lub 410 dla martwych treści zamiast 200 z komunikatem o błędzie.
- Wyczyść mapy witryny. Podziel je, jeśli są duże. Trzymaj się limitów 50k adresów lub 50 MB na plik, dodaj
<lastmod>w formacie ISO i upewnij się, że wszystkie wpisy zwracają 200, są kanoniczne i indeksowalne. Kompresuj duże pliki gzipem i hostuj pod stabilnym adresem. - Zwaliduj dane uporządkowane. Używaj JSON-LD dla artykułów, produktów, breadcrumbs i organizacji. Upewnij się, że schema odzwierciedla treść na stronie i linkuje do kanonicznego adresu. Napraw ostrzeżenia blokujące kwalifikację do rich results.
- Obsłuż nawigację fasetową w skali. Zezwalaj na indeksację wartościowych kombinacji, ale blokuj lub noindex resztę. Unikaj linkowania do nieskończonych kombinacji sortowań i filtrów. Dla widoków niekanonicznych ustaw canonical do kategorii bazowej.
- Poprawnie ustaw sygnały międzynarodowe i GEO. Wdroż hreflang z kodami język-region jak
en-US, dodaj x-default i zachowaj self-referencing canonicals per lokalizacja. Unikaj automatycznych geo-redirectów, które uniemożliwiają crawlowanie.
Czysta indeksacja pomaga także w widoczności w wyszukiwaniu AI. Gdy sygnały kanoniczne, dane strukturalne i świeżość są wiarygodne, odpowiedzi AI chętniej cytują i poprawnie streszczają Twoje strony.
Priorytetyzuj poprawki
- Oceń każde zagadnienie przez pryzmat wpływu i wysiłku. Użyj prostego modelu ICE: Impact x Confidence / Effort. Najpierw realizuj pozycje z wysokim wynikiem. Prowadź jednostronicowy tracker, aby każdy widział kolejkę i właścicieli.
- Najpierw usuń blokery. Napraw błędy 5xx, zbłąkane reguły noindex, uszkodzone kanoniki i pętle przekierowań przed mikrooptymalizacjami. Odblokuj crawlowanie i renderowanie, potem iteruj nad szybkością.
- Dostarczaj szybkie wygrane CWV. Preloaduj zasoby hero, odłóż analytics, ustaw
font-display: swap, określ wymiary obrazów i usuń martwe skrypty. To zwykle poprawia LCP i CLS w dni, nie tygodnie. - Ustandaryzuj przekierowania i kanoniki. Stwórz globalne zasady dla hosta, protokołu, ukośników końcowych i wrażliwości na wielkość liter. Zapewnij jednoetapowe 301, aby nie marnować crawla i nie rozpraszać sygnałów.
- Wdrażaj per szablon, potem mierz. Wdróż na jednym szablonie, zrób ponowny crawl, a następnie obserwuj trendy w GSC i RUM przez dwa tygodnie przed skalowaniem. To zmniejsza ryzyko i dowodzi przyczynowości.
- Zautomatyzuj monitoring i alerty. Włącz alerty e-mail GSC, checki uptime, próbkowanie logów pod kątem skoków 4xx/5xx oraz budżety CWV z alertami, gdy LCP lub INP przekroczą progi.
- Dokumentuj zmiany z timestampami. Prowadź changelog z tym, co, kiedy, gdzie i dlaczego się zmieniło. Dodawaj adnotacje w GA4 i narzędziu do monitoringu pozycji. Gdy pozycje się zmienią, połączysz przyczynę i skutek.
- Traktuj to jako proces ciągły, nie jednorazowy. Połącz tę listę z niezawodną automatyzacją SEO, taką jak RankGoat, aby crawlowanie, CWV i indeksacja były zdrowe z miesiąca na miesiąc.
Zdrowie techniczne wzmacnia wszystko, co robisz. Usługa blogów done-for-you i silny link building przynoszą zwrot, gdy strony są szybko crawlowane, czysto renderowane i indeksowane bez zamieszania. Cennik RankGoat odzwierciedla fakt, że miesięczna usługa obejmuje poprawki techniczne wraz z treściami i linkami, więc nie musisz żonglować dostawcami ani panelami.
Najważniejsze wnioski
- Zacznij od dostępu, bazowych pomiarów i jasnych zasad dla canonicali, ukośników i parametrów.
- Usuń marnotrawstwo crawla, łańcuchy przekierowań i błędy z logów, aby chronić budżet crawlowania.
- Najpierw priorytetyzuj poprawy Core Web Vitals, które wpływają na realnych użytkowników.
- Trzymaj mapy witryny w czystości i utrzymuj spójne sygnały, aby poprawić indeksację i widoczność w AI search.
- Zamień audyt w proces cykliczny z właścicielami, SLA i alertami.
Dodaj tę listę do zakładek, uruchamiaj ją co kwartał i przypisz właścicieli. Jeśli wolisz oddać to w dobre ręce, RankGoat wykonuje te kontrole ciągle, jednocześnie publikując nowe treści i zdobywając dofollow linki, abyś mógł skupić się na biznesie.
Najczęstsze pytania
- Jak często wykonywać audyt SEO techniczny? Pełny audyt rób kwartalnie, a lżejszą, comiesięczną kontrolę Core Web Vitals, indeksacji i krytycznych problemów z crawlem. Po większych zmianach w serwisie wykonaj audyt ad hoc.
- Jakie szybkie poprawki Core Web Vitals działają na większości stron? Preloaduj obraz hero, kompresuj i zmieniaj rozmiary mediów, odkładaj skrypty niekrytyczne i usuń nieużywane tagi zewnętrzne. To zwykle szybko poprawia LCP, CLS i INP.
- Jak zdecydować, co oznaczyć noindex, a co skanonikalizować? Skanonikalizuj bliskie duplikaty wariantów, które chcesz konsolidować, a noindex zastosuj do stron cienkich lub niskiej wartości, których w ogóle nie chcesz w wyszukiwarce. W mapach witryny zostawiaj tylko kanoniczne, wartościowe adresy URL.
- Czy poprawki techniczne mogą poprawić widoczność w wynikach AI? Tak. Jasne kanoniki, czyste mapy witryny, poprawne schema i szybkie strony pomagają systemom wyszukiwania crawlować, rozumieć i ufać Twoim treściom, co wspiera uwzględnianie ich w odpowiedziach AI.
- Co RankGoat robi poza SEO technicznym? RankGoat prowadzi także usługę pisania blogów done-for-you oraz usługę pozyskiwania backlinków, więc produkcja treści i zdobywanie linków wspierają ciągłe poprawy techniczne.